Julien Richard-Foy
In a previous blog post, I explained how Scala 2.13’s new collections have been designed so that the default implementations of transformation operations work with both strict and non-strict types of collections. In essence, we abstract over the evaluation mode (strict or non strict) of concrete collection types.
After we published that blog post, the community raised concerns about possible performance implications of having more levels of abstraction than before.
This blog article:
- gives more information about the overhead of the collections’ view-based design and our solution to remove that overhead,
- argues that for correctness reasons it is still better to have view-based default implementations,
- shows that we should expect the new collections to be equally fast
or faster than the old collections, and reports an average speedup
of 35% in the case of
Vector’sfilter,mapandflatMap.
For reference, the source code of the new collections is available in this GitHub repository.
Overhead Of View Based Implementations
Let’s be clear, the view based implementations are in general slower than their
builder based versions. How much slower exactly varies with the type of collection
(e.g. List, Vector, Set), the operation (e.g. map, flatMap, filter)
and the number of elements in the collection. In my benchmark on Vector, on
the map, filter and flatMap operations, with 1 to 7 million of
elements, I measured an average slowdown of 25%.
How To Fix That Performance Regression?
Our solution is simply to go back to builder based implementations for strict collections: we override the default view based implementations with more efficient builder based ones. We actually end up with the same implementations as in the old collections.
In practice these implementations are factored out in traits that can be mixed
into concrete collection types. Such trait names are always prefixed with
StrictOptimized. For instance, here is an excerpt of the StrictOptimizedIterableOps
trait:
trait StrictOptimizedIterableOps[+A, +CC[_], +C] extends IterableOps[A, CC, C] {
override def map[B](f: A => B): CC[B] = {
val b = iterableFactory.newBuilder[B]()
val it = iterator()
while (it.hasNext) {
b += f(it.next())
}
b.result()
}
}
Then, to implement the Vector collection, we just mix such a “strict optimized” trait:
trait Vector[+A] extends IndexedSeq[A]
with IndexedSeqOps[A, Vector, Vector[A]]
with StrictOptimizedSeqOps[A, Vector, Vector[A]]
Here we use StrictOptimizedSeqOps, which is a specialization of StrictOptimizedIterableOps
for Seq collections.
Is The View Based Design Worth It?
In my previous article, I explained a drawback of the old builder based design.
On non strict collections (e.g. Stream or View), we had to carefully override all the
default implementations of transformation operations to make them non strict.
Now it seems that the situation is just reversed: the default implementations work well with non strict collections, but we have to override them in strict collections.
So, is the new design worth it? To answer this question I will quote a comment posted by Stefan Zeiger:
The lazy-by-default approach is mostly beneficial when you’re implementing lazy collections because you don’t have to override pretty much everything or get incorrect semantics. The reverse risk is smaller: If you don’t override a lazy implementation for a strict collection type you only suffer a small performance impact but it’s still correct.
In short, implementations are correct first in the new design but you might want to override them for performance reasons on strict collections.
Performance Comparison With 2.12’s Collections
Talking about performance, how performant are the new collections compared to the old ones?
Again, the answer depends on the type of collection, the operations and the number of elements.
My Vector benchmarks show a 35% speedup on average:
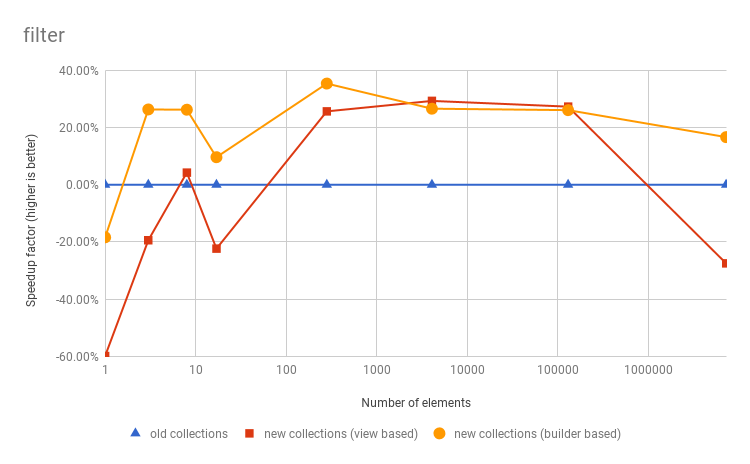
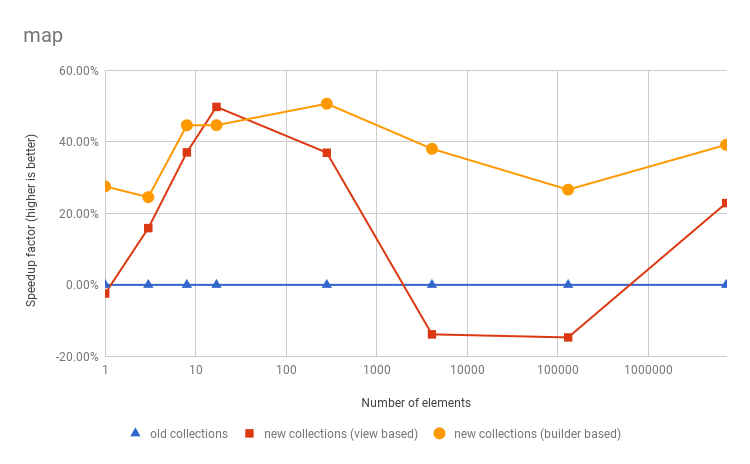
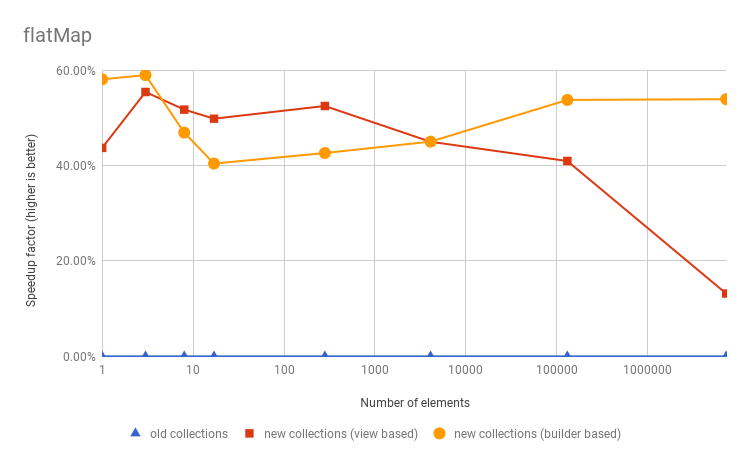
These charts show the speedup factor (vertically) of the filter, map and flatMap
operations execution compared to the old Vector, for various number of elements (horizontally).
The blue line shows the old Vector,
the red line shows the new Vector if it used only view based
implementations, and the yellow line shows the actual new Vector
(with strict optimized implementations). See Benchmark source code and numbers.
Since operation implementations end up being the same, why do we get better performance
at all? Well, these numbers are specific to Vector and the tested operations, they
are due to the fact that
we more aggressively inlined a few critical methods. I don’t expect the new collections
to be always faster than the old collections. However, there is no reason for
them to be slower since the execution path, when calling an operation, can be made
exactly the same as in the old collections.
Conclusion
This article studied the performance of the new collections. I’ve reported that view based operation implementations are about 25% slower than builder based implementations, and I’ve explained how we restored builder based implementations on strict collections. Last but not least, I’ve shown that defaulting to view based implementations does make sense for the sake of correctness.
I expect the new collections to be equally fast or slightly faster than the previous collections. Indeed, we took advantage of the rewrite to apply some more optimizations here and again.
More significant performance improvements can be achieved by using different
data structures. For instance, we recently
merged
a completely new implementation of immutable Set and Map based on compressed
hash-array mapped prefix-trees.
This data structure has a smaller memory footprint than the old HashSet and HashMap,
and some operations can be an order of magnitude faster (e.g. == is up to 7x faster).