Monday 28 August 2017
Michael Viveros
Introduction
One problem with open-source software is that it can be difficult to find a project to contribute to and actually get started contributing to it. Some open-source projects can seem very intimidating to newcomers since they have a very large code base and minimal documentation about how to get involved with the project. Other projects make it easier for prospective contributors to localize and figure out how to participate in a project, having for example:
- a contributing guide with specific steps that potential contributors can follow to get involved
- some well-documented, easy to fix, beginner-friendly issues which are great places to learn about the project and get started contributing
- a chatroom/forum like gitter where anyone can come and easily ask questions
For Google Summer of Code 2017, my project was to make it easier for potential contributors to both find projects to contribute to and to get started contributing to projects, all through Scaladex (the Scala Library Index). I accomplished this by highlighting projects that have Contributing Info (contributing guide, beginner-friendly issues and chatroom) on the front page of Scaladex so that potential contributors can easily view projects that they could contribute to and see all the information necessary for contributing in one place. I also added a Contributing Search page which can be used to query these projects.
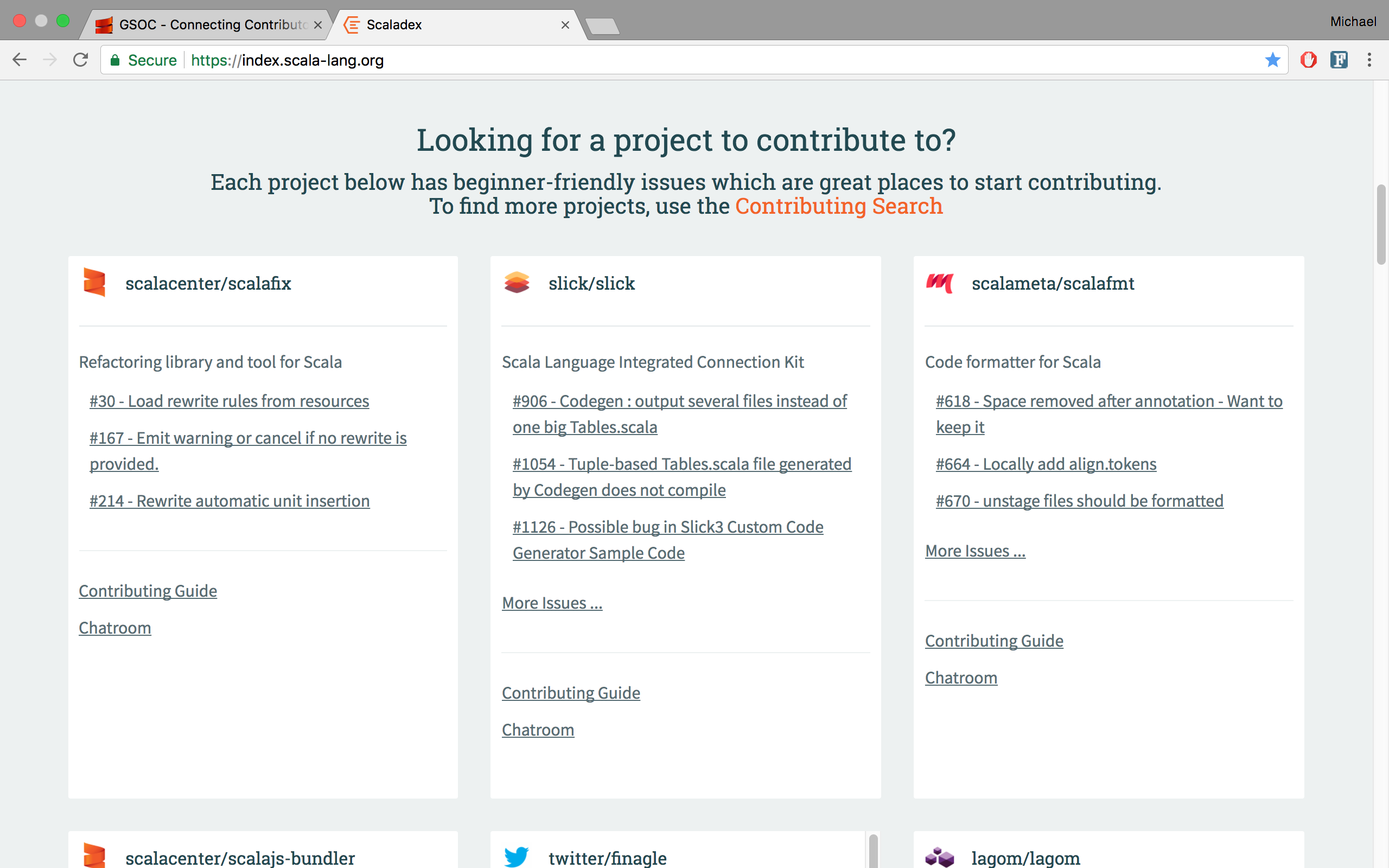 Highlighted projects with Contributing Info on the front page of Scaladex
Highlighted projects with Contributing Info on the front page of Scaladex
Furthermore, I improved the search feature of Scaladex by adding GitHub Topics to the projects stored in Scaladex so that users can search projects based on Topics. Topics are essentially categories that open-source projects belong to like android, databases, json, …
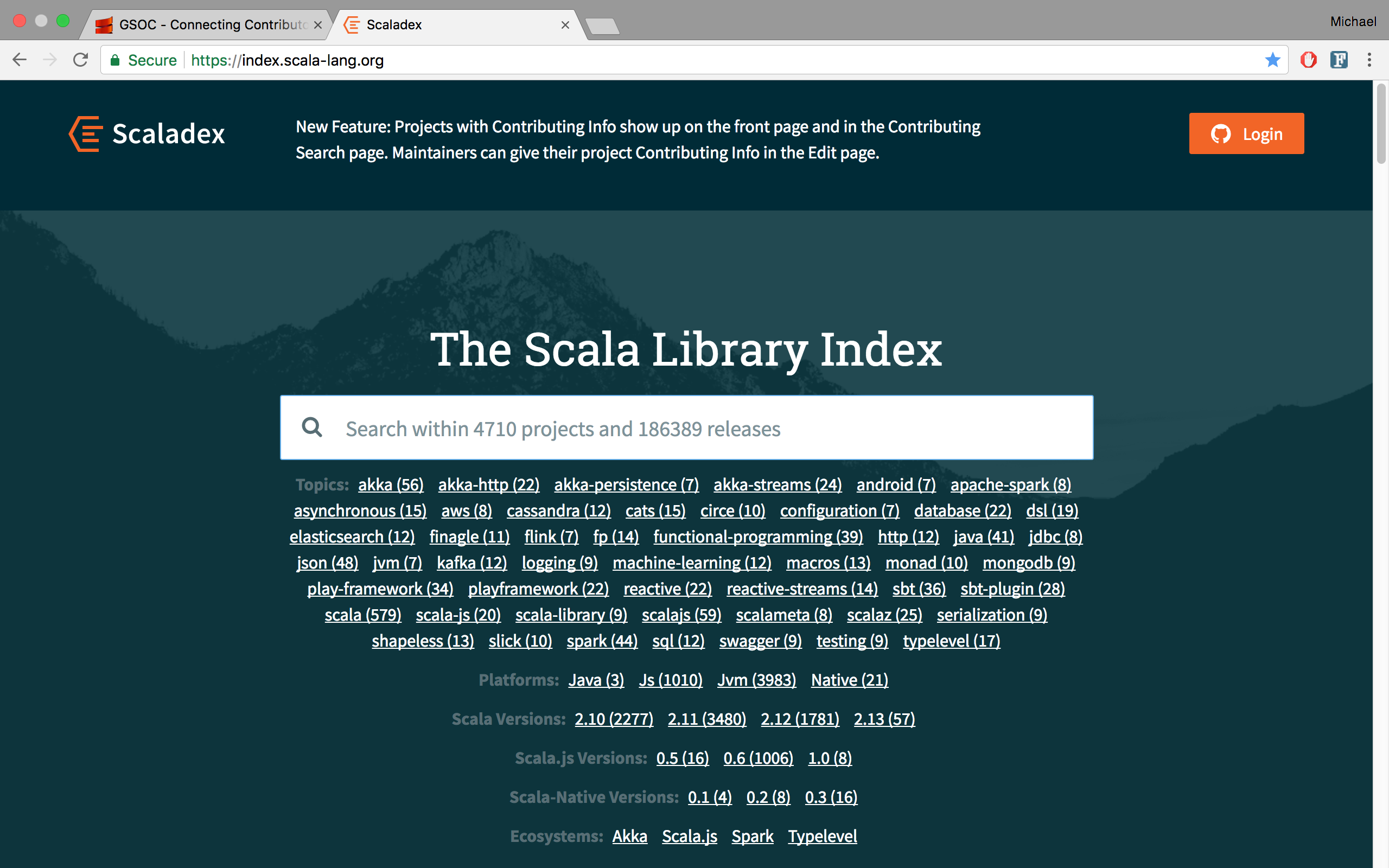 Topics for projects on the front page of Scaladex
Topics for projects on the front page of Scaladex
How to Add Your Project
If you’re a project maintainer and want to add Contributing Info to your project so that it can show up on the front page of Scaladex and in the Contributing Search page, do the following:
- Login to GitHub in Scaladex
- Go to your project’s page in Scaladex and click Edit
- Set the Beginner Issues Label field
- Set the Chatroom field (if it hasn’t been auto-populated)
- Set the Contributing Guide field (if it hasn’t been auto-populated)
Contributing Info
How it Works
To Scaladex, Contributing Info consists of the three pieces of information mentioned above: a contributing guide, a collection of beginner-friendly issues, and a link to a chatroom/forum for the project where newcomers can come to easily ask questions. And perhaps most importantly; Scaladex can automatically obtain much of this info for your project! It’s also possible for a project maintainer to manually set this information on their project’s edit page in Scaladex.
Here’s some more info about how each piece of contributing info gets set:
- beginner-friendly label/issues - first the label used to identify beginner-friendly issues has to be manually set in the edit page, then Scaladex will fetch the corresponding issues
- chatroom - auto-populated to a project’s gitter room if it has one
- contributing guide - auto-populated to a project’s CONTRIBUTING.md if it has one
As an example, the Scaladex project (for the code behind the website) uses the label “low-hanging fruit” to mark beginner-friendly issues in GitHub so this label can be set by the maintainer in the edit project page and all the issues with this label will be stored for this project. It also has a gitter room for chatting and a contributing guide which will be auto-populated for the project when all the projects are indexed.
Scaladex uses GitHub’s GraphQL API to get a project’s beginner-friendly issues, see the GitHub Topics section below for more info about GitHub’s GraphQL API. To get a project’s contributing guide, Scaladex uses GitHub’s REST API to send a GET request to the Community Profile API which will return links to a project’s contributing guide, code of conduct and license. Lastly, to get a project’s chatroom, Scaladex generates a URL for a project’s gitter room based on the project’s repository name and the organization it belongs to (Ex. https://gitter.im/scalacenter/scaladex) and checks if that URL exists.
You can also find Contributing Info on the front page of Scaladex. Now, Scaladex highlights a random subset of projects which have Contributing Info on the front page of Scaladex. It picks a random selection of projects each time the page is loaded to give the same amount of exposure to all projects with Contributing Info. We hope to highlight and better guide potential contributors to projects and issues that are of interest to them!
The Contributing Search page is similar to the normal search page in Scaladex where you can search projects based on keywords but it only shows projects that have Contributing Info and instead of just showing a project’s description in the search results, it shows Contributing Info for each result. Additionally, the Contributing Search page does filtering on a project’s beginner-friendly issues. For example, if you enter a search term related to documentation like “docs”, the search results will contain issues related to documentation for each project.
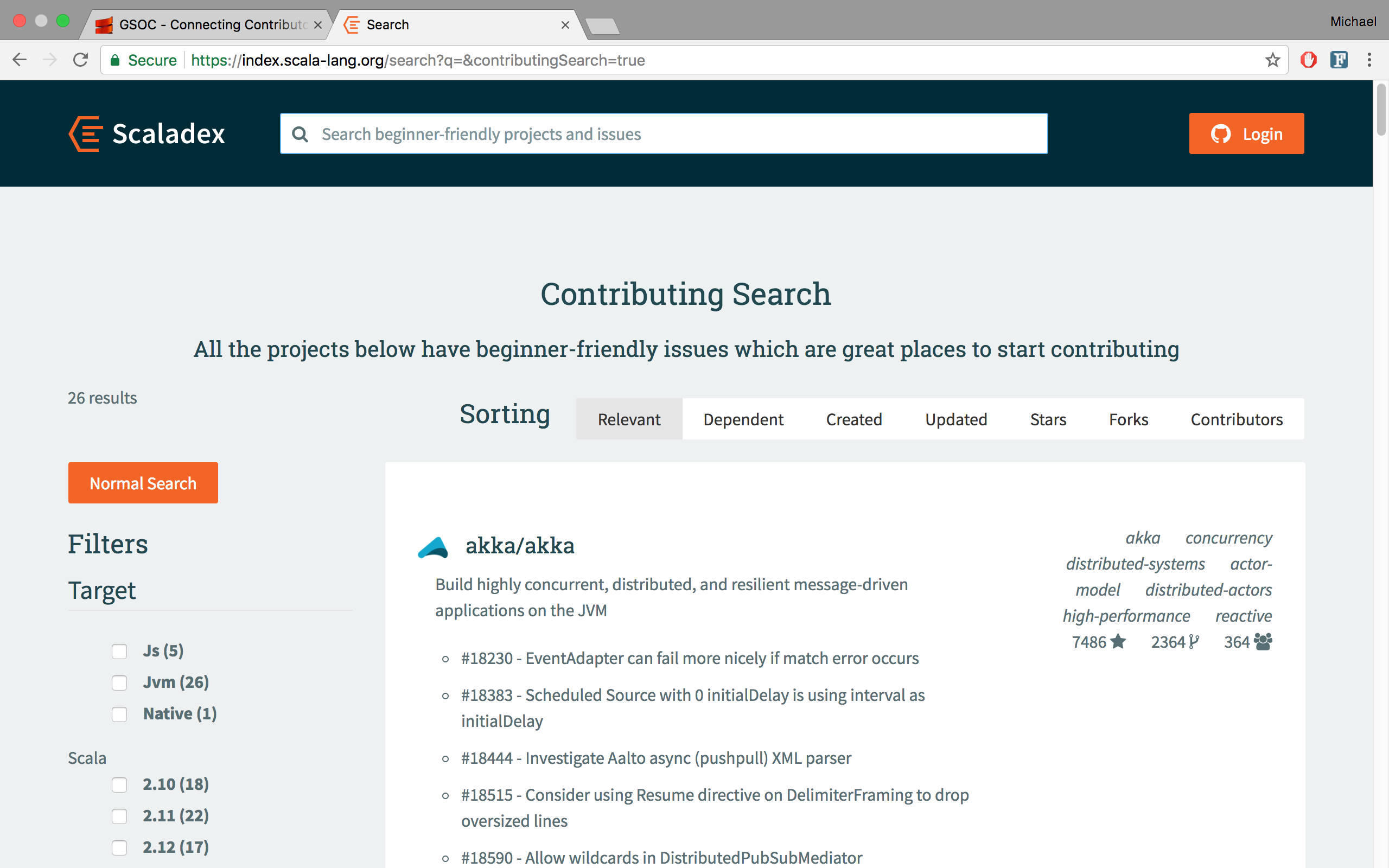 The Contributing Search page in Scaladex which shows Contributing Info like beginner-friendly issues for each result
The Contributing Search page in Scaladex which shows Contributing Info like beginner-friendly issues for each result
Code
The code for Contributing Info was committed in 2 pull requests, 1 for the back-end and 1 for the front-end.
Challenge
One interesting challenge I ran into was filtering a project’s issues based on a search term. For example, say a user is searching for all issues related to documentation so they enter “docs” as a search term in the Contributing Search page. A project called akka-http has some beginner-friendly issues, one of which is related to documentation with the title “#22874 - Add examples to Sink.actorRefWithAck and Source.queue docs”. Since this is the only issue for akka-http that has “docs” in its title, it should be the only issue that shows up for akka-http in the search results.
All the projects in Scaladex are stored in an Elasticsearch index which is like a database in a relational database. Each project stored in Elasticsearch has the following fields:
name: Text
description: Text
isDeprecated: Boolean
github: Object
readme: Text
commits: Long
beginnerIssues: Nested
number: Long
title: Text
...
Each project has a github field of type Object containing GitHub info like a project’s readme and its number of commits. The github field has a beginnerIssues field which is a list of a project’s beginner-friendly issues. The beginnerIssues field is of type Nested, which is a special version of the Object type used for lists of Objects. Each issue in beginnerIssues is of type Object and it has a number field and a title field.
When Scaladex generates a search query to match the input search term (“docs” from the example above) to an Elasticsearch query, all you have to do to match the search term against a project’s beginner-friendly issues is add a Nested Query against the github.beginnerIssues field and specify you want to match the search term against the issue’s title field. So this is the Nested Query I added to DataRepository.scala which generates the Elasticsearch query:
nestedQuery("github.beginnerIssues",
termQuery("github.beginnerIssues.title", searchTerm))
This sort of worked. It would return the correct projects that have issues matching the search term, but instead of returning only the issues related to the search term, it would return all the issues. So in the example with the “docs” search term, all of akka-http’s issues would be returned, not just the one related to documentation.
After looking through the Elasticsearch documentation for a while, I came across Inner Hits which can be used with Nested Queries to select out the nested inner objects that matched the query. So inner hits would return only the beginner-friendly issues that matched the search term. So I updated the code that creates the Nested Query to also extract the inner hits that get returned:
nestedQuery("github.beginnerIssues",
termQuery("github.beginnerIssues.title", searchTerm))
.inner(innerHits("issues").size(7))
And then I added the filtered beginner-friendly issues from inner hits to the project that gets created from the results of the Elasticsearch query. I did this by updating the code in package.scala that reads in each result of the Elasticsearch query (hit) and converts it to a Scala Project object which is used by the server elsewhere.
implicit object ProjectAs extends HitReader[Project] {
override def read(hit: Hit): Either[Throwable, Project] = {
val project = nread[Project](hit.sourceAsString).copy(id = Some(hit.id))
val projectWithFilteredIssues = hit.asInstanceOf[RichSearchHit].innerHits
.get("issues")
.collect {
case searchHits if searchHits.totalHits > 0 => {
p.copy(
github = p.github.map { github =>
github.copy(
beginnerIssues = searchHits
.getHits()
.map { hit =>
nread[GithubIssue](hit.getSourceAsString)
}
.toList
)
}
)
}
}
.getOrElse(p)
tryEither(projectWithFilteredIssues))
}
}
GitHub Topics
How it Works
To categorize projects in Scaladex, the old process was for project maintainers to manually set keywords for their project in Scaladex. Users could then search for projects based on keywords.
GitHub recently added “topics” to projects stored in GitHub which are labels that can be set for a project corresponding to categories that a project belongs to. Topics are essentially the same as keywords in Scaladex but maintainers could set them for their project in GitHub instead of having to do so in Scaladex.
Topics are part of GitHub’s new GraphQL API which is meant to eventually replace their old REST API. GraphQL is a “A query language for your API”. It is both a query language and a graph-structured schema which stores data with nodes as objects and edges as relationships between objects. It was developed by Facebook and is different from a traditional REST API by having all API requests go to one route and having a query defined in the request body to specify precisely what data you want.
With GitHub’s REST API, you have to make multiple requests to different routes to get project info about multiple projects. And when you make a request, all the data related to that request would be returned. For example, if you wanted to get the most recent 3 issues created for 5 different projects, you would make 5 requests to 5 different routes for each project. Each request would return all the project’s issues. With the GraphQL API, all requests are made to the same route and in the body of the request you input a GraphQL query which specifies exactly what information you want and for which projects. So for the example above of getting the most recent 3 issues created for 5 projects, you would make 1 request to 1 route containing a query to get only the 3 most recent issues for the 5 projects and only those 3 issues for each of the projects would be returned. This results in less requests to GitHub’s API and less data returned in each response.
So I replaced keywords with topics for projects in Scaladex and used GitHub’s new GraphQL API to fetch the topics. These topics are fetched for all projects when the server is indexed. A lot more projects have topics than keywords (which had to manually be set by maintainers in Scaladex), so this greatly improved the ability to search for projects based on categories in Scaladex since there are a lot more projects with categories.
Here’s the code I added to GithubDownload.scala which contains the GraphQL query that is put in the POST body of the request sent to GitHub’s GraphQL API to fetch topics for a project. You can see the graph-structure of GraphQL in the query. The query first gets a repository node and then accesses its topics through the repositoryTopics edge/connection. Then it selects the names of the topics belonging to that repository.
private def topicQuery(repo: GithubRepo): JsObject = {
val query =
"""
query($owner:String!, $name:String!) {
repository(owner: $owner, name: $name) {
repositoryTopics(first: 50) {
nodes {
topic {
name
}
}
}
}
}
"""
Json.obj(
"query" -> query,
"variables" -> s"""{ "owner": "${repo.organization}", "name": "${repo.repository}" }"""
)
}
If you run that query for the akka project, this is what gets returned from the GitHub API:
{
"data": {
"repository": {
"repositoryTopics": {
"nodes": [
{
"topic": {
"name": "reactive"
}
},
{
"topic": {
"name": "distributed-systems"
}
},
{
"topic": {
"name": "concurrency"
}
},
{
"topic": {
"name": "high-performance"
}
},
{
"topic": {
"name": "akka"
}
},
{
"topic": {
"name": "actor-model"
}
},
{
"topic": {
"name": "distributed-actors"
}
}
]
}
}
}
}
Code
The code for GitHub Topics was committed in one pull request.
Closing Remarks
Huge thanks to my mentor Heather Miller who was very approachable and always took the time to discuss the best way to implement this project.
Also thanks to Guillame Massé for being a super dev teammate and to Julien Richard-Foy for providing great feedback on my pull requests.